
Automating Alumni Counts on LinkedIn
An Insight into Top Business, Medical, and Law Schools

Why Automate?
Gathering accurate and updated alumni data manually from LinkedIn is time-consuming and tedious. With automation, we streamline this process, ensuring accuracy and efficiency while providing valuable insights quickly.
Web scraping is a powerful tool for automating data extraction from websites. In this article, we will discuss how to automate the process of scraping school rankings and alumni data, such as those found in the table above, using Python and libraries like BeautifulSoup and Selenium.
The Automation Setup
I used Python along with Selenium and WebDriver-Manager to automate the extraction of alumni counts from LinkedIn for the top 20 schools in three prestigious fields: Medicine, Law, and Business.
The libraries used:
selenium: Automates browser tasks.requests: To fetch web pages.BeautifulSoup: To parse and extract data from HTML.pandas: To store and analyze the extracted data.webdriver-manager: Manages browser drivers efficiently.
How It Works:
The script:
Logs into LinkedIn automatically.
Visits alumni pages for each top school.
Extracts the alumni count for each specified field (Medical, Law, Business).
Understanding the Data
The dataset includes:
Rankings: The best schools in each category extracted from US news.
Alumni Numbers: The number of alumni for each school.
Timestamps: The date and time when the rankings were published.
Setting Up the Environment
Ensure you have the necessary libraries installed:
pip install requests beautifulsoup4 selenium pandasWriting the Scraper
Below is a basic Python script to scrape school rankings and alumni data:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website containing rankings (example placeholder)
URL = 'https://example.com/top-schools'
# Fetching the page
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Extracting data (adjust selectors as needed)
rankings = []
alumni_numbers = []
for row in soup.select('table tr')[1:]: # Skipping header row
cells = row.find_all('td')
if len(cells) > 0:
rankings.append({
'Category': cells[0].text.strip(),
'School': cells[1].text.strip(),
'Alumni': int(cells[2].text.replace(',', ''))
})
# Creating a DataFrame
rankings_df = pd.DataFrame(rankings)
# Saving to CSV
rankings_df.to_csv('school_rankings.csv', index=False)
print("Data scraping completed and saved to school_rankings.csv")Handling Dynamic Content
If the website loads content dynamically, Selenium can be used:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
# Setting up Selenium
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get(URL)
data = []
rows = driver.find_elements(By.CSS_SELECTOR, "table tr")
for row in rows[1:]:
cells = row.find_elements(By.TAG_NAME, "td")
if len(cells) > 0:
data.append({
'Category': cells[0].text.strip(),
'School': cells[1].text.strip(),
'Alumni': int(cells[2].text.replace(',', ''))
})
# Creating a DataFrame
driver.quit()
df = pd.DataFrame(data)
df.to_csv('dynamic_school_rankings.csv', index=False)
print("Dynamic content scraping completed.")Insights from the Data extracted on July 21, 2024:
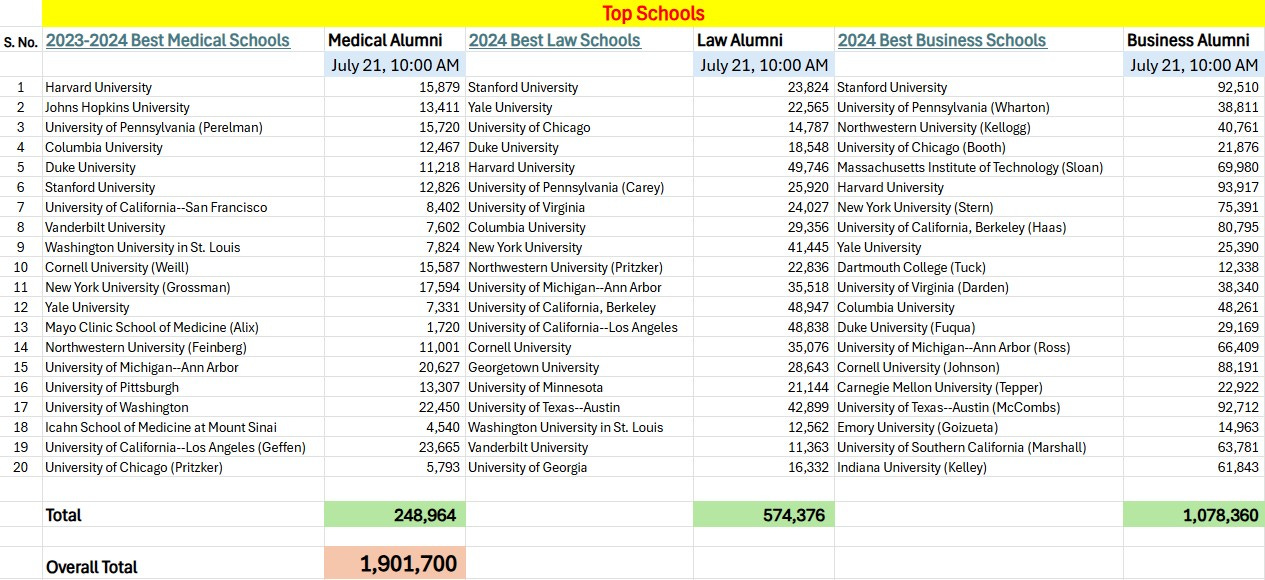
Here are some fascinating takeaways from the data extraction done on July 21, 2024:
Medical Alumni:
Highest: University of California—Los Angeles (Geffen) – 23,665 alumni
Total medical alumni from top 20 medical schools: 248,964
Law Alumni:
Highest: Harvard University – 49,746 alumni
Total law alumni from top 20 law schools: 574,376
Business Alumni:
Highest: Harvard University – 93,917 alumni
Total business alumni from top 20 business schools: 1,078,360
Key Observations:
Harvard University consistently shows strong representation, leading in both Law and Business.
Business schools significantly surpass Medical and Law schools in terms of LinkedIn alumni counts, highlighting possibly broader career paths or network utilization in business fields.
Best Practices
Respect Robots.txt: Always check the website's
robots.txtfile to ensure compliance.Use Headers and Delays: To avoid getting blocked, use request headers and sleep intervals.
Store Data Efficiently: Save results in CSV or databases for further analysis.
Access the Code
For those interested in exploring the code in more detail, I have uploaded the Jupyter Notebook containing the web scraping implementation to my GitHub repository. You can access it here:
🔗 GitHub Repository - LinkedIn Scraper
Feel free to clone, modify, and experiment with the code for your own projects!
Future Possibilities:
Automation can be extended to analyze career outcomes, geographic distributions, or industry-specific breakdowns of alumni. This enables further strategic insights for recruiters, educational institutions, or prospective students.
Final Thoughts:
Automating LinkedIn data collection unlocks new opportunities to understand professional networks and educational outcomes deeply. By harnessing automation, we leverage data-driven decisions to enhance education, hiring, and networking practices.
Feel free to share your thoughts or any further ideas on automation applications!